چتجیپیتی (ChatGPT) یکی از پیشرفتهترین مدلهای زبانی در جهان هوش مصنوعی است که برای تولید پاسخهای هوشمندانه و دقیق استفاده میشود. اما دقیقاً چه چیزی باعث میشود این مدل تا این حد قوی و هوشمند باشد؟ در این مقاله به زبان ساده و محاورهای و البته کمی تخصصی، نحوه عملکرد چتجیپیتی را بررسی میکنیم.
1. چتجیپیتی مثل یک دانشمند خستگی ناپذیر
تصور کنید چتجیپیتی مثل یک دانشمند پرمطالعه است که از هزاران کتاب، مقاله و وبسایت خوانده و همه را به خاطر سپرده است. اما برخلاف ما انسانها که با مفهوم و احساسات درک میکنیم، چتجیپیتی به جای فهم عمیق، از یک سیستم ریاضی پیچیده به نام پردازش زبان طبیعی (NLP) استفاده میکند تا اطلاعات را ذخیره و تحلیل کند.
2. مرحله اول: کلمات به زبان ماشین ترجمه میشوند
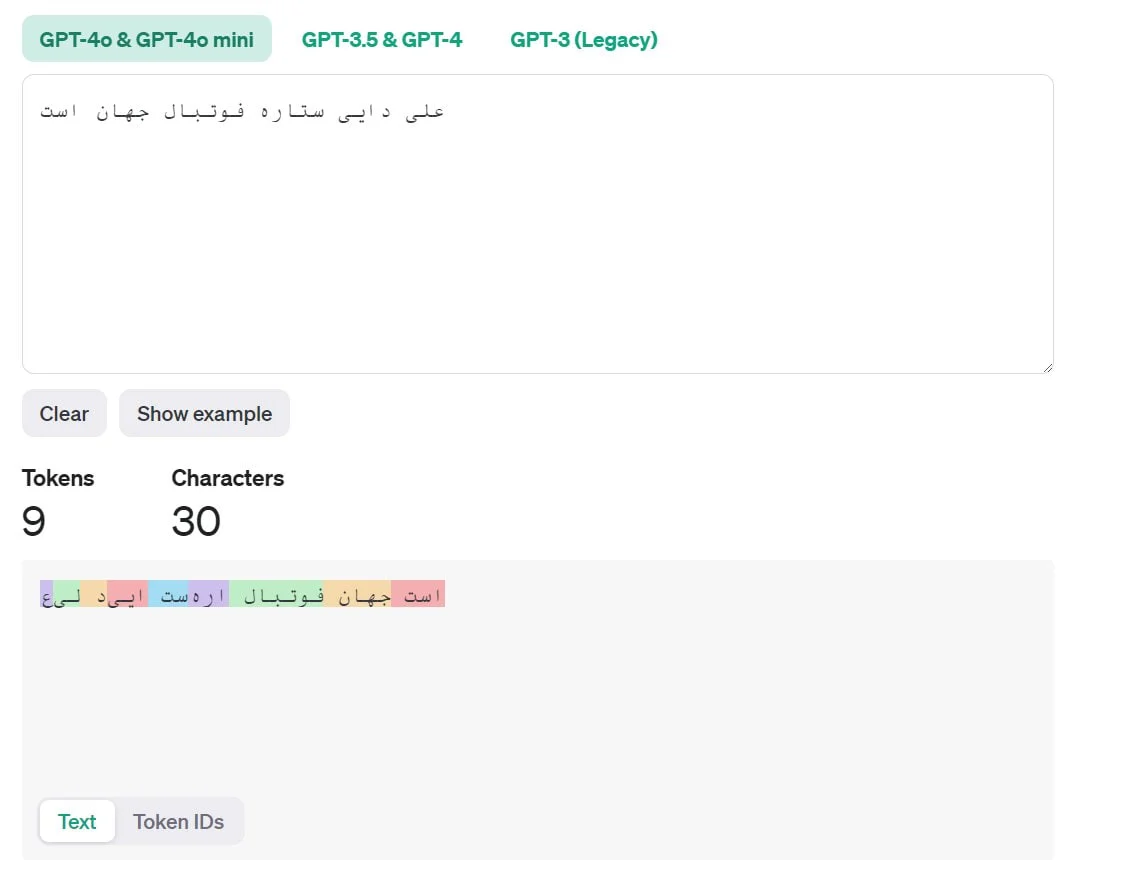
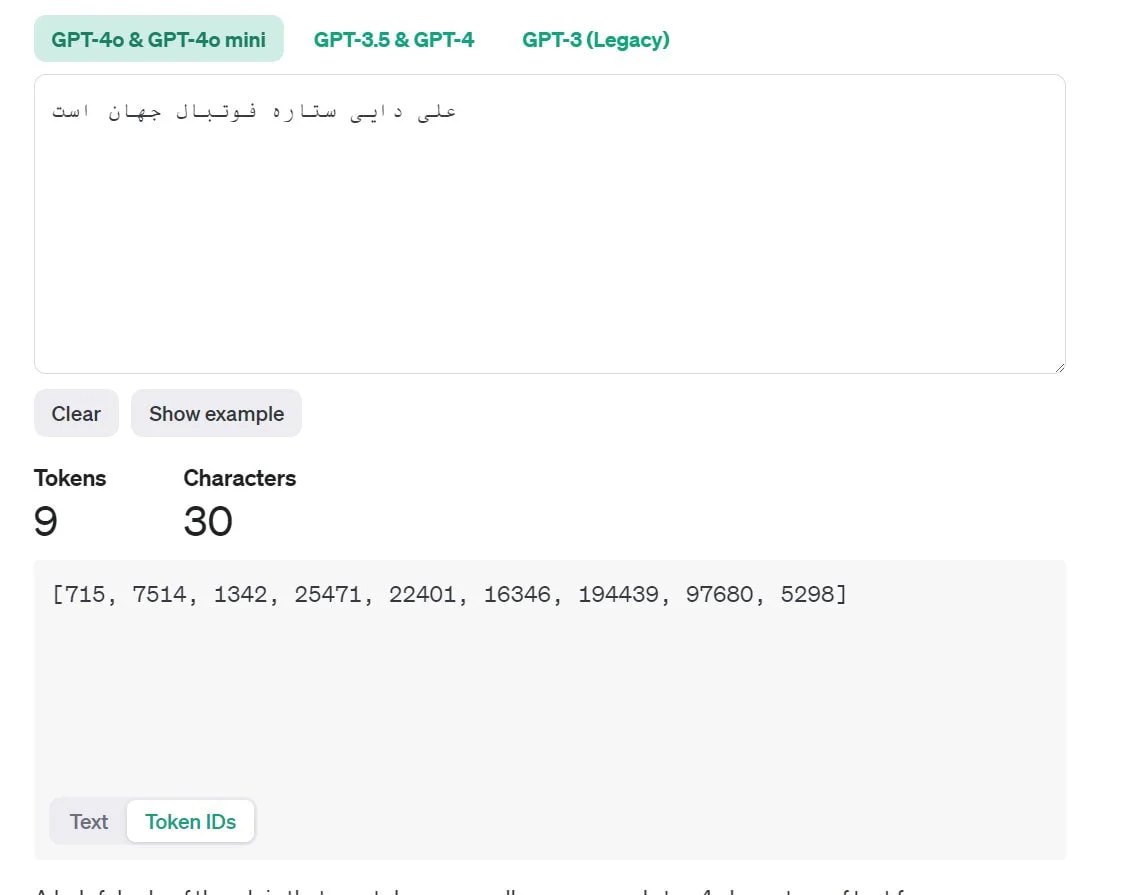
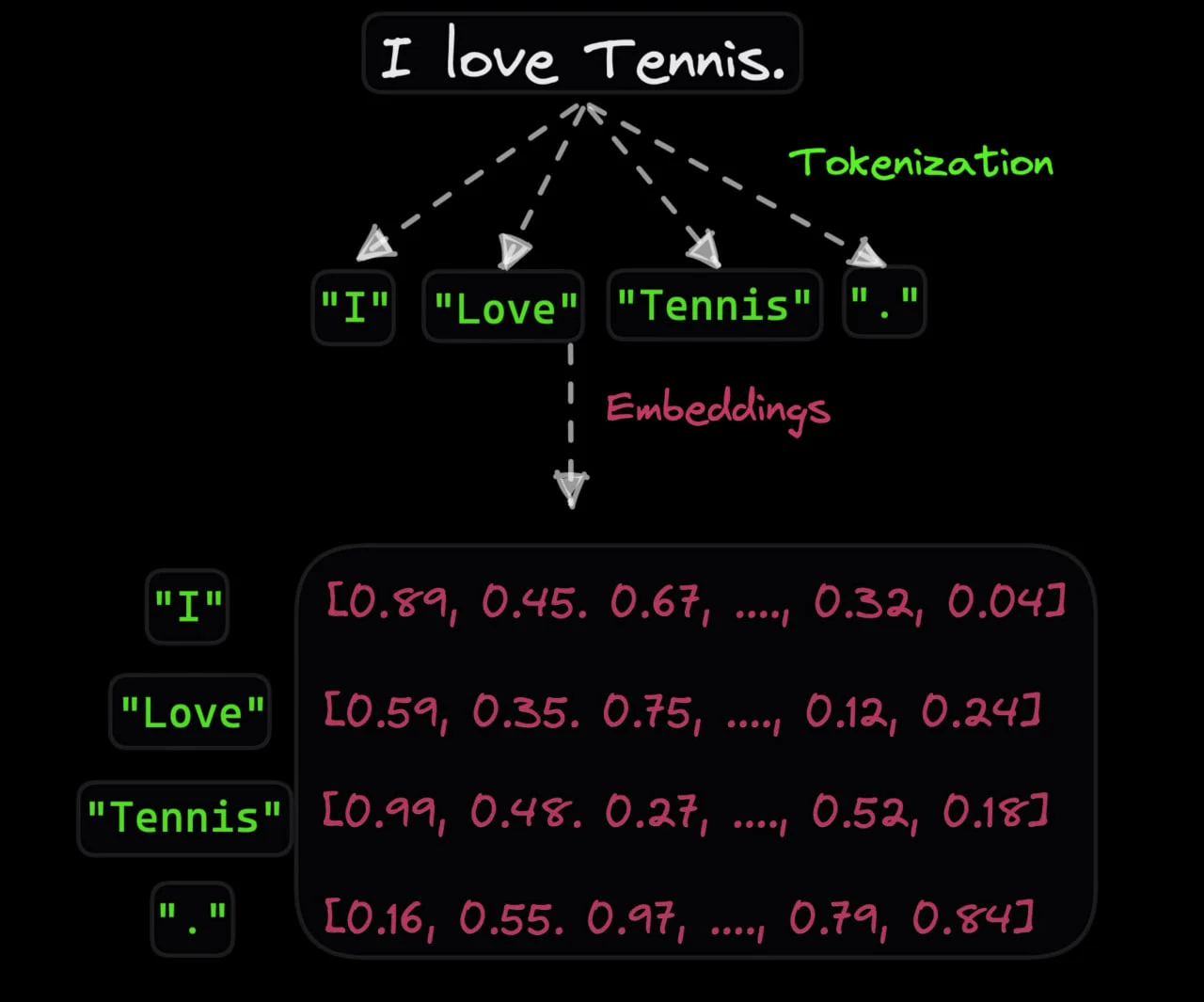
وقتی سوالی مثل “چگونه کیفیت عکس را افزایش دهم؟” میپرسید، چتجیپیتی ابتدا سوال شما را به واحدهای کوچکی به نام توکن تبدیل میکند. هر توکن میتواند یک کلمه، بخشی از کلمه یا حتی علامتها باشد. این توکنها در یک فضای ریاضی به نام فضای برداری قرار میگیرند و موقعیتهای خاصی پیدا میکنند.
توضیح بیشتر برای متخصصان: این فرآیند به کمک مدلهای ترانسفورمر انجام میشود که معماری پایه آنها با مقاله معروف “Attention Is All You Need” معرفی شد.
3. مرحله دوم: مکانیزم توجه (Attention Mechanism)
چتجیپیتی از مکانیزم توجه استفاده میکند تا بفهمد کدام قسمتهای سوال شما مهمتر هستند و باید بیشتر روی آنها تمرکز کند. به زبان ساده، این ویژگی به مدل کمک میکند به جای پردازش یکسان همه کلمات، بیشتر روی کلمات کلیدی مثل “کیفیت” و “عکس” تمرکز کند.
مفهوم کلیدی: مکانیزم توجه مانند یک چراغ قوه است که به مدل اجازه میدهد بر بخشهای مهمتر دادهها تمرکز کند و اطلاعات بهینهای را برای پاسخ آماده کند.
4. پردازش اطلاعات و فیلتر کردن
چتجیپیتی با استفاده از الگوریتمهایی مثل ReLU (Rectified Linear Unit) دادههای اضافی و غیرضروری را فیلتر میکند. این باعث میشود فقط اطلاعات مهم و مرتبط در حافظه باقی بماند و پاسخهای دقیقتری تولید شود.
مثال عملی: اگر بپرسید “آیا خورشید بزرگتر از زمین است؟”، چتجیپیتی بخشهایی از اطلاعاتش را که به فضا، اندازه و سیارات مربوط میشود، انتخاب و بقیه اطلاعات مانند نام سیارات دیگر را حذف میکند.
5. ترکیب اطلاعات و تولید پاسخ
بعد از پردازش دادهها، مدل شروع به ترکیب اطلاعات و تولید پاسخ میکند. این مرحله شبیه چیدن قطعات پازل است که مدل باید مطمئن شود قطعات درست در کنار هم قرار بگیرند تا پاسخی مناسب بسازد.
نمونه پاسخ برای کاربر: اگر از چتجیپیتی بپرسید “چگونه کیفیت عکس را بهصورت رایگان بهبود دهم؟”، او میتواند به شما توضیح دهد که از ابزارهای هوش مصنوعی استفاده کنید و حتی شما را به مقاله افزایش کیفیت تصاویر با هوش مصنوعی هدایت کند.
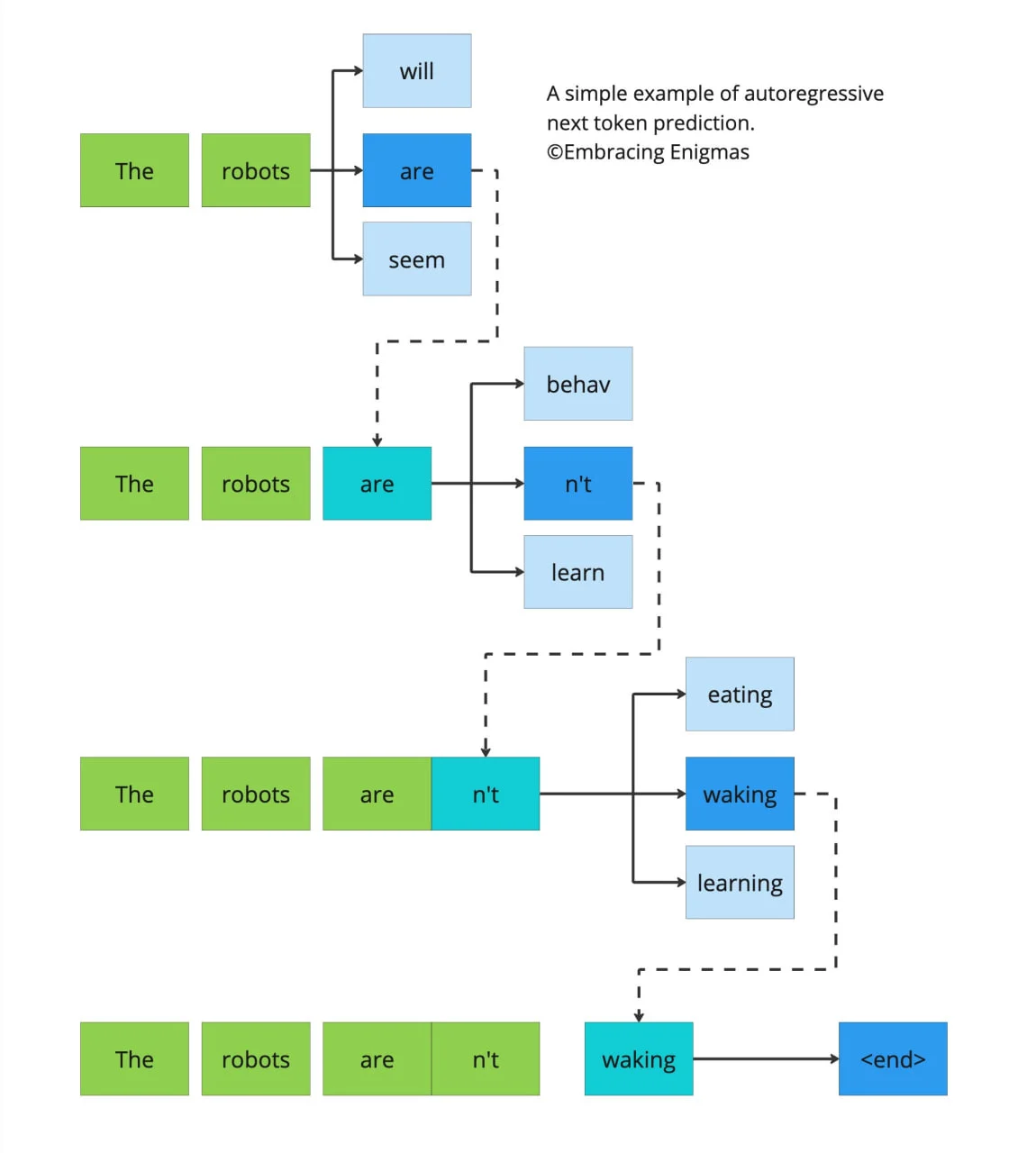
6. آیا چتجیپیتی واقعاً مفهوم را میفهمد؟
این سوالی است که ذهن بسیاری را درگیر کرده است. پاسخ این است که چتجیپیتی دقیقاً مانند انسان مفهوم را نمیفهمد. او الگوهای متنی را میشناسد و براساس این الگوها پیشبینی میکند که بهترین پاسخ کدام است. به همین دلیل گاهی ممکن است جوابهایی بدهد که دقیق یا کاملاً درست نباشند.
برای متخصصان: چتجیپیتی از روشهای پیشرفتهای مثل شبکههای عصبی بازگشتی (RNN) و شبکههای عصبی پیشخور (Feedforward) استفاده نمیکند و کاملاً بر پایه ترانسفورمرها است که به پردازش موازی اطلاعات کمک میکنند.
7. چرا چتجیپیتی گاهی اشتباه میکند؟
چتجیپیتی بر اساس دادههایی که آموزش دیده، پاسخ میدهد. اگر دادهها ناقص یا دارای خطا باشند، پاسخها هم ممکن است اشتباه باشند. این مدل نمیتواند اطلاعاتی که به او داده نشده یا آموزش ندیده است را خلق کند. مثل دوستی که داستانی شنیده و آن را بازگو میکند؛ اگر جزئیاتی را اشتباه شنیده باشد، در نقل آن هم دچار اشتباه خواهد شد.
معرفی سرچ جی پی تی انقلاب جدید در جستجو
شرکت OpenAI با ارائه SearchGPT قصد دارد به رقابت با موتورهای جستجوی بزرگ مثل گوگل و بینگ بپردازد. این سرویس میتواند پاسخهای دقیق و بهروزی را به کاربران ارائه دهد و حتی از اطلاعات مکانی برای بهبود نتایج استفاده کند. برای کسب اطلاعات بیشتر، پیشنهاد میکنیم به مقاله معرفی قابلیت جستجوی ChatGPT نگاهی بیندازید.
نتیجهگیری: آینده چتجیپیتی و مدلهای مشابه
چتجیپیتی به عنوان یکی از پیشرفتهترین مدلهای هوش مصنوعی، همچنان در حال پیشرفت است. محققان به دنبال مدلهایی هستند که سبکتر، کارآمدتر و هوشمندتر باشند. شاید روزی برسد که این مدلها توانایی درک مفاهیم را مانند انسان داشته باشند.
اگر علاقهمند به یادگیری بیشتر در مورد چتجیپیتی و نحوه استفاده از آن هستید، میتوانید دورههای رایگان ChatGPT را بررسی کنید و دانش خود را گسترش دهید.
در ادامه بخشی تخصصیتر و جامعتر درباره مدلهای زبانی بزرگ (LLM) و فناوریهای مربوطه مینویسم اگر یوزر عادی هستید ممکنه نیاز نباشه بصورت تخصصی ادامه این مقاله رو بخونید و این بخش صرفا برای افراد متخصص در این حوزه است.
نگاهی تخصصی به مدلهای زبانی بزرگ (LLM)
مدلهای زبانی بزرگ (LLM)، از جمله چتجیپیتی (ChatGPT)، ابزارهای پیچیدهای هستند که توسط شبکههای عصبی مصنوعی با ابعاد عظیم ساخته شدهاند. این مدلها برای پردازش و تولید زبان طبیعی طراحی شدهاند و قادرند با حجم زیادی از دادههای متنی آموزش ببینند و ارتباطات پیچیده بین کلمات و جملات را درک کنند.
معماری و ساختار مدلهای LLM
مدلهایی مانند GPT-3 و GPT-4 بر پایه معماری ترانسفورمر (Transformer) بنا شدهاند. این معماری با ارائه مکانیزم توجه (Attention Mechanism) انقلابی در پردازش زبان طبیعی به وجود آورد و جایگزین روشهای سنتیتر مانند شبکههای عصبی بازگشتی (RNN) و شبکههای عصبی پیچشی (CNN) شد.
مکانیزم توجه به مدل کمک میکند تا ارتباط بین کلمات در جملات طولانی را به خوبی شناسایی کند و به آنها وزندهی مناسب بدهد. به بیان ساده، این تکنیک به مدل اجازه میدهد هنگام پردازش جمله، تمرکز خود را بر کلمات مهمتر قرار دهد و از اطلاعات متنی بهینه استفاده کند.
توکنسازی و نحوه پردازش دادهها
هر جمله یا ورودی متنی در مدلهای زبانی بزرگ به واحدهای کوچکی به نام توکن تقسیم میشود. این توکنها شامل کلمات، بخشهایی از کلمات یا حتی نمادهای خاص هستند. با استفاده از توکنساز (Tokenizer)، هر کلمه به یک عدد یا بردار در فضای برداری تبدیل میشود. این بردارها با کمک تعبیههای کلمهای (Word Embeddings) در فضای چندبعدی مدل قرار میگیرند و ارتباط بین آنها براساس شباهت معنایی تعیین میشود.
یادگیری و بهینهسازی مدلها
LLMها با استفاده از یادگیری نظارتشده (Supervised Learning) و یادگیری بدون نظارت (Unsupervised Learning) آموزش میبینند. یکی از الگوریتمهای معروف برای آموزش این مدلها بهینهسازی گرادیان نزولی (Gradient Descent) است که به کمک تابع زیان (Loss Function) میزان خطای مدل را کاهش میدهد.
پیشآموزش (Pre-training) و آموزش تکمیلی (Fine-tuning) دو مرحله مهم در ساخت LLMها هستند:
پیشآموزش: مدل در این مرحله با حجم عظیمی از دادههای عمومی (مانند مقالات، کتابها و صفحات وب) آموزش داده میشود تا اصول و الگوهای پایه زبان را بیاموزد.
آموزش تکمیلی: این مرحله به مدل اجازه میدهد برای وظایف خاصتر (مثل مکالمه یا ترجمه) بهینه شود.
محدودیتها و چالشها در مدلهای LLM
مدلهای زبانی بزرگ با همه پیشرفتهایشان، محدودیتهایی دارند:
نیاز به منابع پردازشی بالا: آموزش مدلهای بزرگ مانند GPT-4 به قدرت محاسباتی عظیم و منابع سختافزاری پیشرفته نیاز دارد.
خطاهای احتمالی: گاهی مدلها اطلاعات نادرست یا غیرواقعی ارائه میدهند. این خطاها ناشی از دادههای ناقص یا الگوریتمهای آموزشیافته هستند.
عدم فهم مفهومی: این مدلها نمیتوانند مفاهیم را مانند انسان درک کنند و بیشتر براساس الگوهای آماری عمل میکنند.
آینده مدلهای LLM
پژوهشگران به دنبال توسعه مدلهای زبانی سبکتر و کارآمدتری هستند که ضمن کاهش نیاز به منابع سختافزاری، دقت بیشتری در تولید زبان داشته باشند. ترکیب فناوریهای یادگیری انتقالی (Transfer Learning) و پردازش تطبیقی (Adaptive Learning) به ایجاد مدلهایی منجر میشود که قادرند با حجم داده کمتر، یادگیری عمیقتری داشته باشند.
mmdmb
میلیون ها کیلومتر اسکرول کردم تا به هدفم نزدیک تر بشم